Entropic Measuring of MNIST Images
All code used in this article can be found on my GitHub page and is written in Python using NumPy.
Introduction
The MNIST database of handwritten digits is commonly used as an example problem for an introduction to machine learning. Each sample is a 28x28 image with the typical goal of classifying which digit is contained in the image. Each image contains 784 pixels, taking on 1 of 256 intensity values, however, not every pixel is equally important for classification. In other words, each pixel contains a different amount of information.
Imagine you are given a blank image where you have the ability to measure individual pixel values and are tasked with determining what it is an image of. If these measurements are expensive, dangerous, or destructive, we obviously need to minimize how many measurements we take. The question then becomes: “Which pixels should be measured?”. To answer this, we turn to information theory, or more specifically, entropy.
Background
Entropy is a measure of how much information a random variable contains or how much information is required to describe a probability distribution. For a random variable X drawn from a probability distribution p and an alphabet 𝓧, entropy is defined as

This equation comes from the additive properties of information and the multiplicative properties of the probabilities of independent random events. Note that we assume 0log(0) = 0 here. For an additional random variable Y, which is independent of X, and an alphabet 𝓨, joint entropy is defined as

Lastly, if Y is dependent on X, conditional entropy is defined as

Calculating MNIST Entropy
For simplicity, we round all MNIST pixel values to be either 0 or 255, which we’ll refer to as “dark” or “bright” pixels respectively.

For a given pixel, the average value over all samples gives us the probability of that pixel being dark or bright.

Next, for a given pixel again, we take the number of occurrences that this pixel is bright for a given class, normalized by the number of occurrences that pixel is bright over all classes. If that pixel is bright, this gives us the probability that the image belongs to that class.

Note that the missing pixels correspond to instances when that pixel is dark for all samples. We can perform a similar analysis for dark pixels.

Note that we do not get the same phenomenon as with the missing bright pixels.
Combining these, we have p(x, y) as the probability that pixel x is bright or dark and the image corresponds to class y. This can also be written as p(x, y) = p(x)p(y|x). Using the equations for entropy presented above on each pixel gives us the information contained in each pixel.
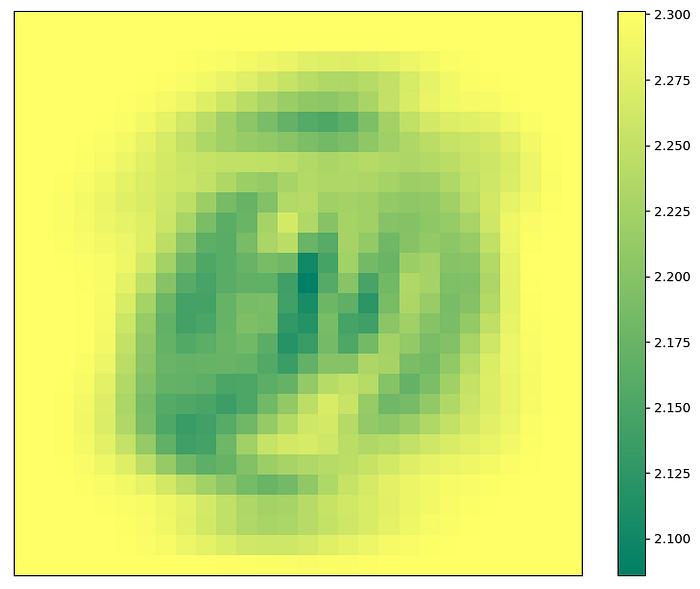
Measuring the MNIST Image
We want to measure the pixel that we expect to contain the most amount of information. To do this, we choose the pixel that has the lowest entropy, as we want to shape the probability distribution of classes towards being 1 for a single class and 0 for all others, which would have an entropy of 0. We expect pixels of maximum entropy to bring us closer to a uniform distribution over all classes as uniform distributions have maximal entropy, thus bringing us no closer to classifying the image.
Once a pixel is measured, we then have a condition on our future probabilities calculations. We repeat the same entropy calculations outlined above, however, our probability distribution is now p(x, y | z) where z is the condition that the pixels we measured are fixed. This process continues until we can determine which class the image belongs to. Below are two examples of this process.
